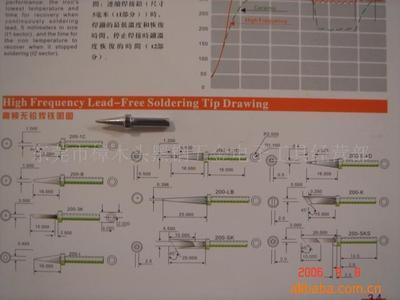
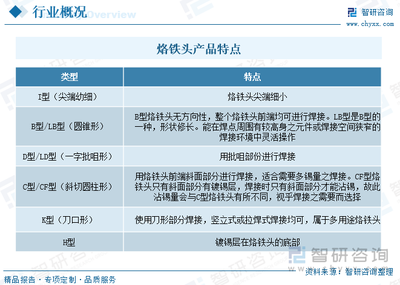
936電焊臺烙鐵頭尖頭刀頭斜頭一字馬蹄頭內熱式60w烙鐵咀無鉛焊頭 - 360購物

如若轉載,請注明出處:http://www.weiyebanjia.cn/product/34.html
更新時間:2026-06-18 10:48:51
產品列表
PRODUCT
----------------
如若轉載,請注明出處:http://www.weiyebanjia.cn/product/34.html
更新時間:2026-06-18 10:48:51
----------------